

Chhorpeanraingsey Thab, Pauruetai Kobsahai, Phongsakorn Thong-aem, Krittapol damrongkamoltip
Feb 27, 2024
ทำไมจึงต้องทำนายโรคหัวใจ?
“หัวใจวาย” เป็นปัญหาสุขภาพที่ร้ายแรงในทั่วโลก อีกทั้งยังมีอัตราการเสียชีวิตเพิ่มสูงและมีแนวโน้มที่จะเพิ่มขึ้นอย่างต่อเนื่อง การคาดการณ์โรคหัวใจวายตั้งแต่เนิ่นๆ จึงเป็นส่วนสำคัญของการวิจัยทางการแพทย์ และปัจจุปันที่ความก้าวหน้าของการวิเคราะห์ข้อมูล จึงทำให้การคาดการณ์นั้นมีความแม่นยำมากยิ่งขึ้น ทำให้เห็นถึงแนวโน้มเพื่อคัดกรองของผู้ป่วย
ดังนั้นโปรเจคนี้มุ่งเน้นไปที่การพัฒนาโมเดลเพื่อทำนายความเป็นไปได้ของการเกิดอาการหัวใจวายในแต่ละบุคคลเพื่อช่วยลดอัตราการเสียชีวิตจากโรคหัวใจและลดความเสี่ยงในการเกิดโรคหัวใจ
ภาพรวมของข้อมูล (Overview)
แหล่งข้อมูลที่ใช้ในการวิเคราะห์
ในการทำนายนี้นั้น ได้เลือก Heart Attack Analysis & Prediction Dataset จาก Rashik Rahman มาเป็นชุดข้อมูลในการทำนาย ชุดข้อมูลนี้เป็นชุดข้อมูลที่เกี่ยวกับผลการตรวจร่างกายของผู้ป่วยที่สัมพันธ์กับการเกิดโรคหัวใจ โดยเรามาเริ่มทำความเข้าใจรายละเอียดของข้อมูลกันก่อน ซึ่งชุดข้อมูลนี้ประกอบไปด้วย 14 คอลัมน์ ได้แก่
Age : อายุของผู้ป่วย (ปี)
Sex : เพศของผู้ป่วย
cp : ชนิดของอาการปวดหน้าอก
ค่า 0 : อาการหน้าอกแน่นแบบเฉพาะ (typical angina)
ค่า 1 : อาการหน้าอกแน่นแบบไม่เฉพาะ (atypical angina)
ค่า 2 : อาการปวดที่ไม่เกี่ยวกับหน้าอก (non-anginal pain)
ค่า 3 : ไม่แสดงอาการ (asymptomatic)
trtbps: ความดันโลหิตขณะพัก (เป็นมม. ปรอท)
chol: คอเลสเตอรอลในเลือด (mg/dl) วัดผ่านเซ็นเซอร์ BMI
fbs : (น้ำตาลในเลือดขณะท้องว่าง > 120 mg/dl) (1 = ใช่; 0 = ไม่ใช่)
restecg : ผลการตรวจคลื่นไฟฟ้าหัวใจขณะพัก
ค่า 0 : ปกติ
ค่า 1 : มีความผิดปกติของคลื่น ST-T (ความผิดปกติของคลื่น T และ/หรือ ระดับคลื่น ST สูงหรือต่ำกว่า 0.05 mV)
ค่า 2 : แสดงความเป็นไปได้หรือแน่ชัดของภาวะซ้ายบางส่วนของหัวใจโดยเกณฑ์ของ Estes
thalach : อัตราการเต้นของหัวใจสูงสุดที่ได้
exng : อาการหน้าอกแน่นเนื่องจากการออกกำลังกาย (1 = ใช่; 0 = ไม่ใช่)
oldpeak : ค่า ST depressed เป็นการตรวจการทำงานของหัวใจโดยการออกกำลังกาย
slp : ค่าความชันเมื่อออกกำลังกายระดับเข้มข้น
ค่า 0 : การเต้นของหัวใจอยู่ในระดับดี (Unsloping)
ค่า 1 : การเต้นของหัวใจอยู่ในระดับปกติ (Flatsloping)
ค่า 2 : สัญญาณบอกถึงหัวใจที่ไม่แข็งแรง (Downsloping)
caa : จำนวนหลอดเลือดหลักที่ผ่านการตรวจด้วยเครื่องเอ็กซเรย์มีค่า 0–3
thall : โรคเลือดที่เรียกว่าธาลัสซีเมีย
ค่า 0 : ปกติ (Normal)
ค่า 1 : ประเภทเลือดไหลไปที่กล้ามเนื้อหัวใจบางส่วน (Fixed Defect)
ค่า 2 : ประเภทไม่มีเลือดไหลไปที่กล้ามเนื้อหัวใจ (Reversible Defect)
ค่า 3 : Thalassemia
output : 0 = โอกาสน้อยที่จะเกิดอาการหัวใจวาย 1 = โอกาสมากที่จะเกิดอาการหัวใจวาย
สามารถดูรายละเอียดเชิงลึกได้ ที่นี่
Load Data
เมื่อเรารู้จักกับชุดข้อมูลเเล้ว ในการพัฒนาโมเดลจากข้อมูล เราจะต้องทำการติดตั้ง library ที่จำเป็นเเละ import ชุดข้อมูลเข้ามาก่อน
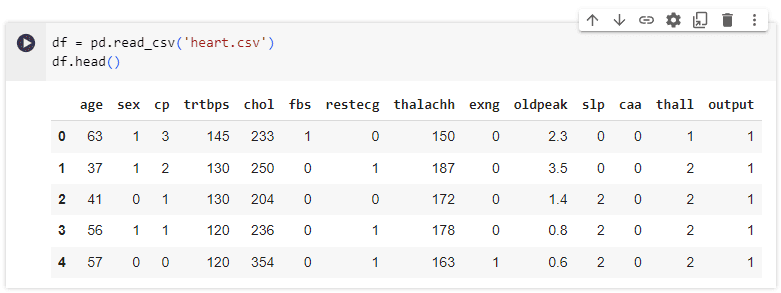
จากนั้นเปิดดูชุดข้อมูลด้วย command: pd.read_csv และ df.head() โดยชุดข้อมูลที่เราใช้คือ heart.csv
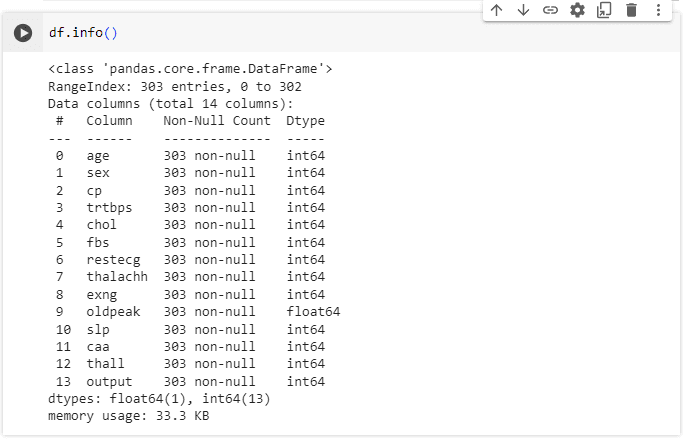
ถัดมาเรามาสำรวจข้อมูลเบื้องต้น ดูความถูกต้องของประเภทข้อมูล (data type) หรือมี missing value หรือไม่ ซึ่งพบว่ามีข้อมูลทั้งหมด 303 รายการ, 14 ตัวแปร (column) ประกอบด้วย 13 integers และ 1 float
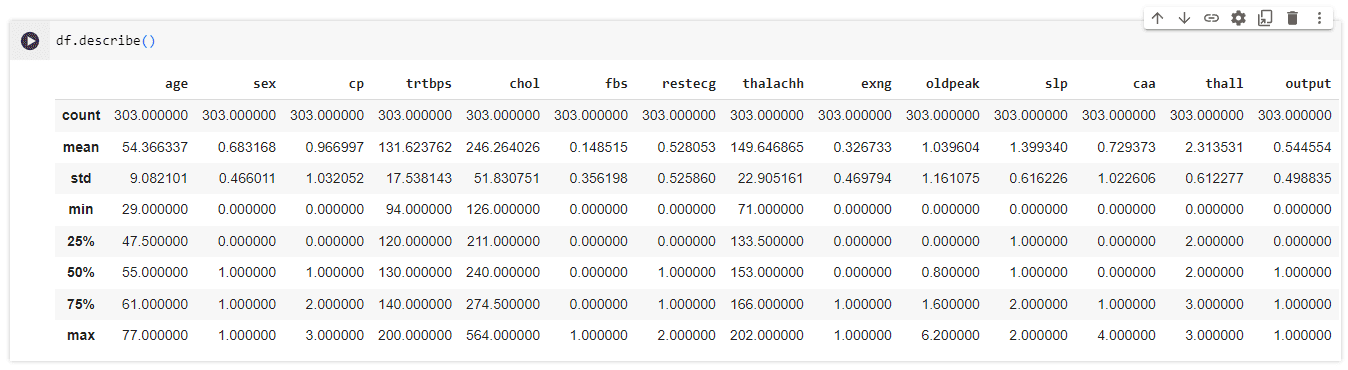
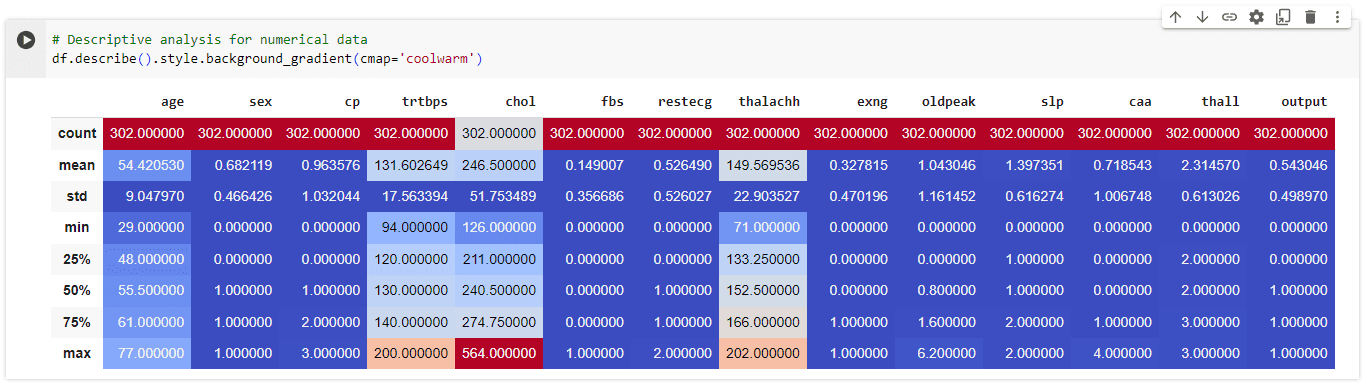
ต่อไปเราทำการสรุปสถิติทั่วไปโดยใช้ คำสั่ง pandas describe function ที่แสดงภาพรวมทั่วไปของการวัดทางสถิติต่างๆ สำหรับคอลัมน์ตัวเลขของชุดข้อมูล
Data cleaning
หลังจากที่เรารู้จักชุดข้อมูลเเล้ว การ cleaning ก่อนจะนำไปใช้ก็สำคัญ โดยใน ขั้นตอนนี้เราเเบ่งเป็น 2 ขั้นตอน ได้เเก่
การหา Null Value
การลบรายการที่ซ้ำกัน (Remove duplicates)
เริ่มจากตรวจสอบว่าภายใน dataset มี Null Value หรือไม่
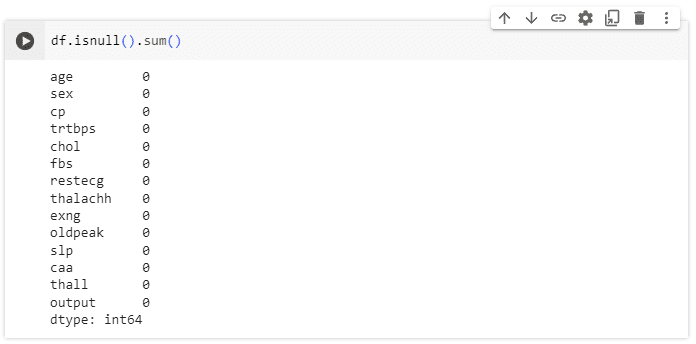

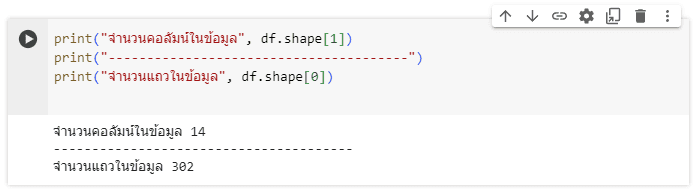
จากรูปจะเห็นได้ว่าไม่มี Null ภายใน dataset แต่!!!! มีรายการซ้ำอยู่ 1 รายการ เราจึงลบรายการที่ซ้ำกันนี้ออกโดยใช้คำสั่ง df.drop_duplicates(inplace=True)และใช้คำสั่ง df.shape เพื่อดูข้อมูลจำนวนแถวและคอลัมน์ของชุดข้อมูลหลังทำการลบเเล้ว
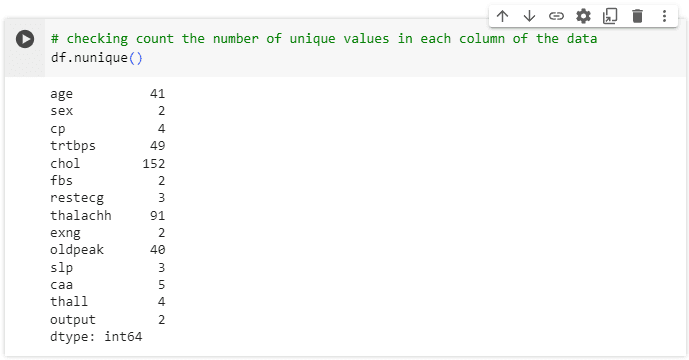
ตรวจสอบค่า Unique ของข้อมูลเเละดูภาพรวมทางสถิติอีกครั้ง
EDA — Exploratory Data Analysis
หลังจากที่เตรียมข้อมูลสำหรับการทำ EDA เเล้ว เรามาเริ่มวิเคราะห์แบบตัวแปรเดียวก่อน โดยทำการพล็อตค่าของชุดข้อมูลในรูปแบบกราฟ
การวิเคราะห์แบบตัวแปรเดียว (Univariate Analysis)
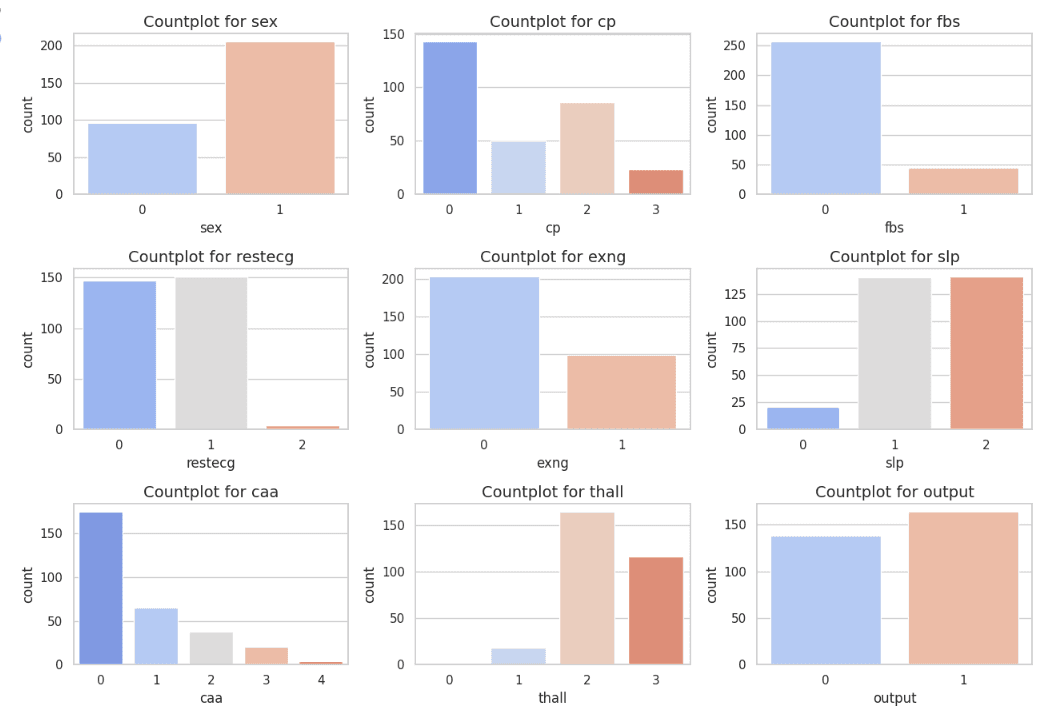
1. Categorical Feature Analysis
เราสังเกตเห็นว่าในชุดข้อมูลนี้หลายคุณลักษณะหมวดหมู่ไม่แสดงความสมดุลในการกระจายของข้อมูล ทำให้บางหมวดหมู่มีจำนวนข้อมูลที่น้อยหรือมากกว่ากลุ่มอื่นอย่างเด่นชัด
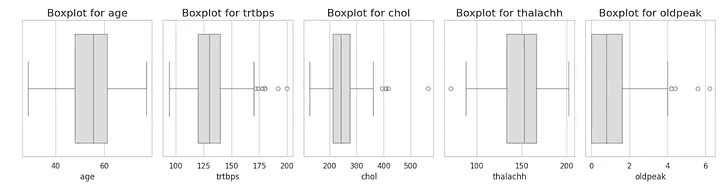
2.Numerical Feature Analysis
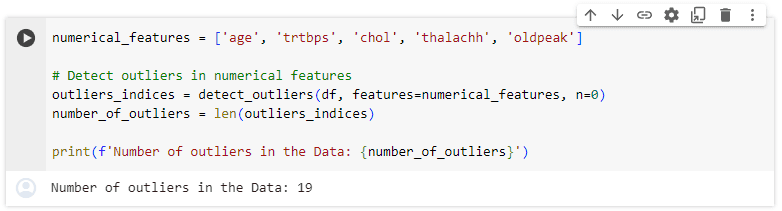
ถัดมาเราพบว่ามี Minor Outliers โดยจำนวนของ outliers ถือว่ามีไม่มากเมื่อเทียบกับขนาดของข้อมูลทั้งหมดและค่อนข้างมีค่าตรงกับแนวโน้มโดยรวมของ dataset เราจึงคาดว่าค่า outliers นี้อาจไม่ได้เกิดจากข้อผิดพลาดในการเก็บข้อมูล (มี outliers เล็กน้อยใน features เเต่สอดคล้องกับรูปแบบของdataset)
การวิเคราะห์แบบสองตัวแปร (Bivariate Analysis)
สำหรับการวิเคราะห์นี้เพื่อดูความสัมพันธ์ระหว่างตัวแปรสองตัว ได้ดังนี้
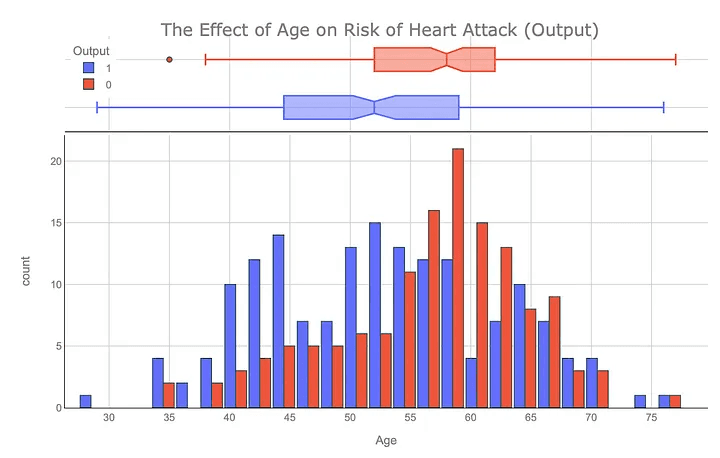
อายุและความเสี่ยงภาวะหัวใจวาย : จากกราฟจะเห็นว่าแค่อายุอย่างเดียวไม่ได้กำหนดความเสี่ยงของภาวะหัวใจวาย และแสดงให้เห็นว่าความเสี่ยงต่อภาวะหัวใจวายแตกต่างกันไปตามกลุ่มอายุ
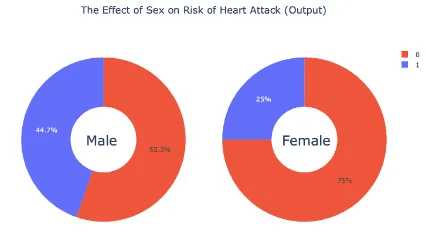
เพศและความเสี่ยงภาวะหัวใจวาย : แผนภูมิวงกลมแสดงให้เห็นว่าผู้ชาย (44.7%) มีแนวโน้มที่จะมีอาการหัวใจวายมากกว่าผู้หญิง (25%)
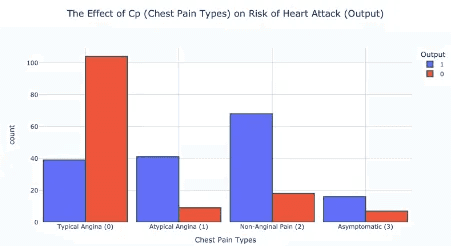
cp (ชนิดของอาการปวดหน้าอก)เเละความเสี่ยงภาวะหัวใจวาย : ผู้ที่มีอาการเจ็บหน้าอกประเภท 2 อาการปวดที่ไม่เกี่ยวกับหน้าอก (non-anginal pain) มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
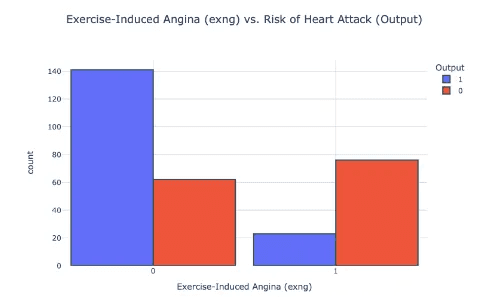
Exng (อาการหน้าอกแน่นเนื่องจากการออกกำลังกาย)และความเสี่ยงภาวะหัวใจวาย : ผู้ที่มีอาการหน้าอกแน่นเนื่องจากการออกกำลังกาย (exng) มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
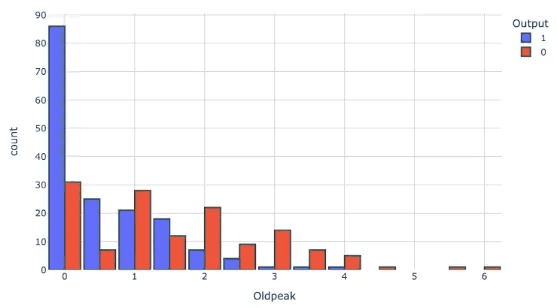
ค่า oldpeak (ค่า ST depressed)และความเสี่ยงภาวะหัวใจวาย : ผู้ที่มีค่า Oldpeak เป็น 0 มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
ค่า slp (ความชันของ ST Segment)และความเสี่ยงภาวะหัวใจวาย : ผู้ที่มีภาวะ slp ประเภท 2 (Upsloping) มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
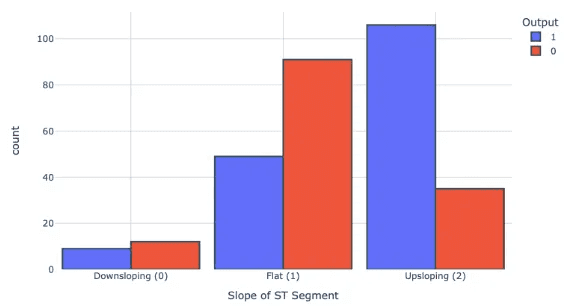
CAA (จำนวนหลอดเลือดใหญ่)และความเสี่ยงภาวะหัวใจวาย : ผู้ที่มีค่า CAA เป็น 0 มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
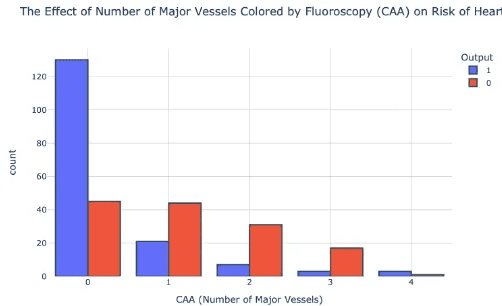
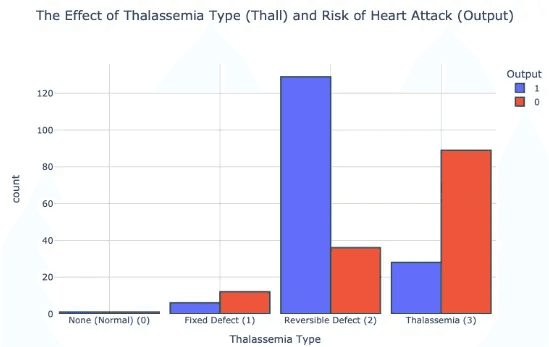
Thall (ธาลัสซีเมีย)และความเสี่ยงภาวะหัวใจวาย : ผู้ที่เป็น Thall ประเภท 2 (Reversible Defect) มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
ดังนั้นสรุปการทำ Bivariate Analysis ได้ว่า
ความเสี่ยงของโรคหัวใจวายเปลี่ยนแปลงตามอายุแต่อายุอย่างเดียวไม่ได้กำหนดความ
เสี่ยงของภาวะหัวใจวาย
ผู้ชายมากกว่า (44.7%) มีแนวโน้มที่จะเกิดโรคหัวใจวายมากกว่าผู้หญิง (25%)
ชนิดของอาการปวดหน้าอกประเภท 2 (non-anginal pain) มีความเสี่ยงของโรคหัวใจวาย
ผลการตรวจคลื่นไฟฟ้าหัวใจประเภท 1 (ความผิดปกติของคลื่น ST-T) นั้นมีความเสี่ยงที่สูงขึ้นของโรคหัวใจวาย
ผู้ที่มีอาการหน้าอกแน่นเนื่องจากการออกกำลังกาย (exng) มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
ค่า Oldpeak เป็น 0 หมายถึงความเสี่ยงที่สูงขึ้นของโรคหัวใจวาย
ผู้ที่อยู่ใน slp ประเภท 2 (Upsloping) มีความเสี่ยงของโรคหัวใจวายมากกว่า
ค่า CAA เป็น 0 มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
ผู้ที่เป็น Thall ประเภท 2 (Reversible Defect) มีแนวโน้มที่จะเป็นโรคหัวใจมากกว่า
การวิเคราะห์แบบหลายตัวแปร (Multivariate Analysis)
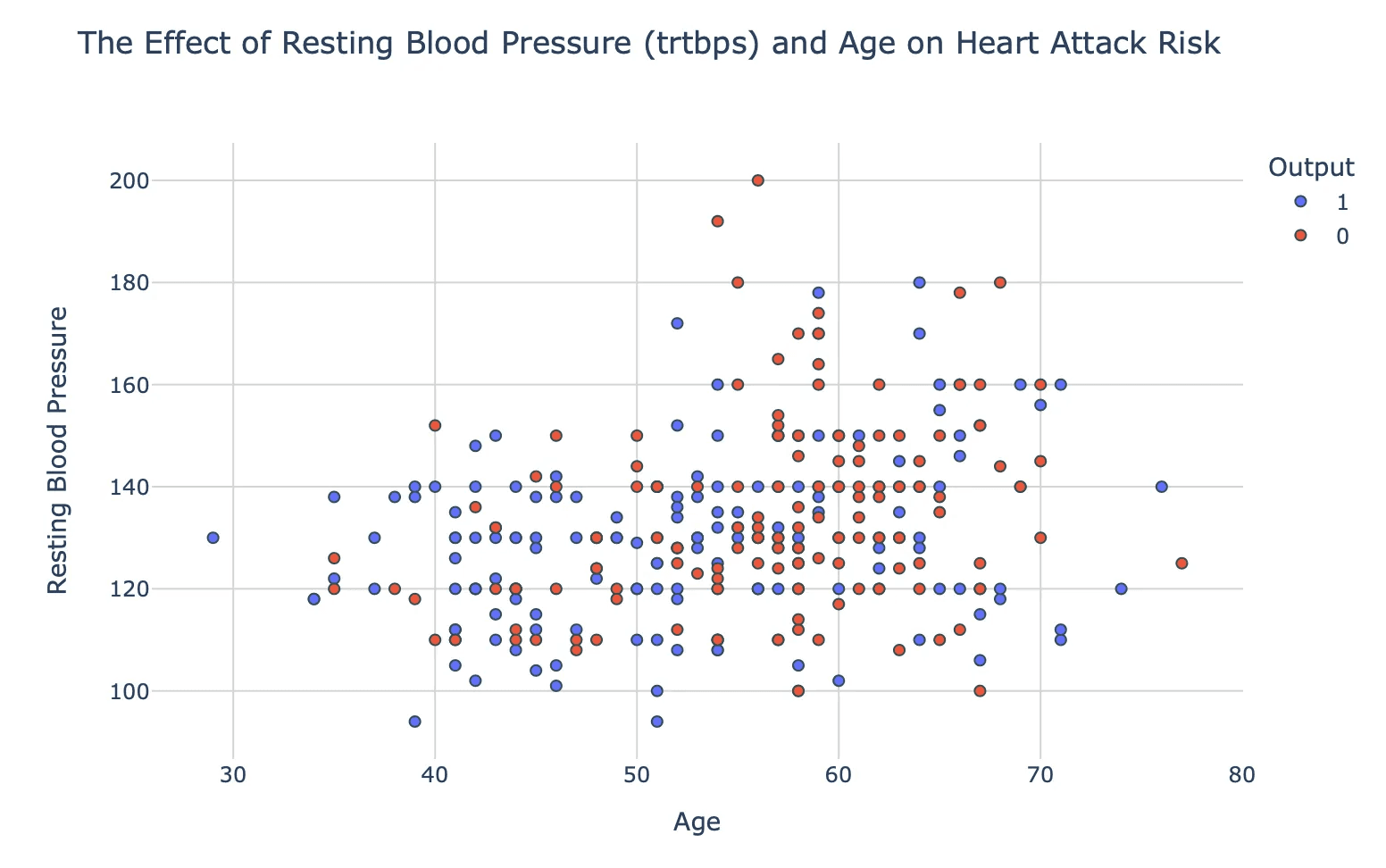
ความดันโลหิตขณะพัก (trtbps) , อายุ เเละความเสี่ยงต่อภาวะหัวใจวาย : กราฟแสดงความสัมพันธ์แบบกระจาย (scatter plot) แสดงถึงความสัมพันธ์ในเชิงบวกระหว่างอายุและความดันโลหิตขณะพัก, โดยคนที่มีอายุมากขึ้นมีความดันโลหิตขณะพักที่สูงขึ้น, ซึ่งอาจเพิ่มความเสี่ยงของการเกิดโรคหัวใจ
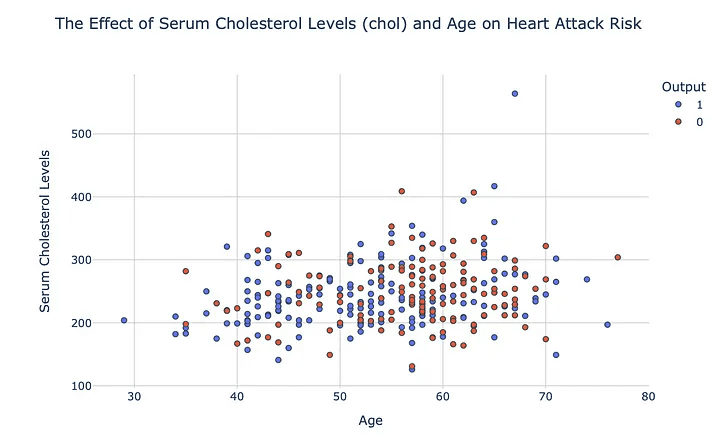
ระดับคอเลสเตอรอลในเลือด (chol) , อายุและความเสี่ยงต่อภาวะหัวใจวาย : แผนภูมิกระจายแสดงความสัมพันธ์เชิงบวกระหว่างอายุและระดับคอเลสเตอรอลในเลือด โดยผู้สูงอายุมักจะมีระดับคอเลสเตอรอลสูงกว่า ซึ่งอาจเพิ่มความเสี่ยงต่อโรคหัวใจวาย
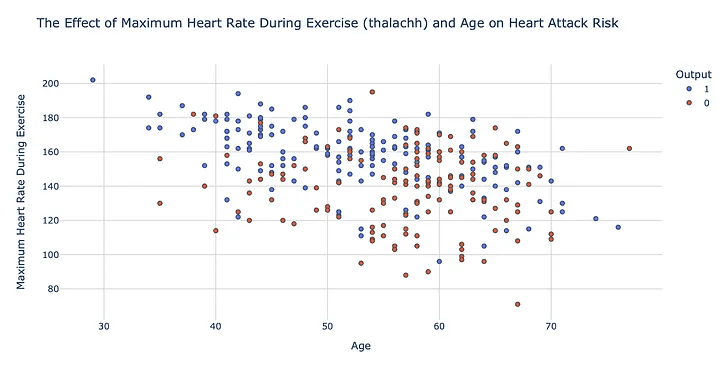
อัตราการเต้นของหัวใจสูงสุดระหว่างออกกำลังกาย (thalachh), อายุและความเสี่ยงต่อภาวะหัวใจวาย : แผนภูมิกระจายแสดงถึงความสัมพันธ์ที่ตรงกันข้ามระหว่างอายุและอัตราการเต้นของหัวใจสูงสุดระหว่างการออกกำลังกายโดยบุคคลที่มีอายุมากขึ้นมักจะมีอัตราการเต้นของหัวใจสูงสุดที่ต่ำลง ซึ่งอาจเพิ่มความเสี่ยงในการเกิดอาการหัวใจวายได้
Heart Attack prediction model
Data Preprocessing
ขั้นตอนนี้เป็นการเตรียมข้อมูลโดยเริ่มจากการตรวจสอบข้อมูลที่หายไป ซึ่งในชุดข้อมูลนี้ไม่มี missing values เราได้จำแนกข้อมูลออกเป็นสองประเภท ได้แก่ หมวดหมู่ที่ไม่มีลำดับ (Nominal Categories) เช่น sex และ หมวดหมู่ที่มีลำดับ (Ordinal Categories) เช่น output ด้วยการใช้ฟังก์ชัน get_dummies และเราได้แปลงข้อมูลเหล่านี้เป็นรูปแบบ one-hot encoding เพื่อนำไปใช้กับโมเดลการเรียนรู้ของเครื่อง นอกจากนี้ ยังได้มีการตรวจสอบและจัดการกับข้อมูลที่เป็น outliers สำหรับการฝึกฝนโมเดล
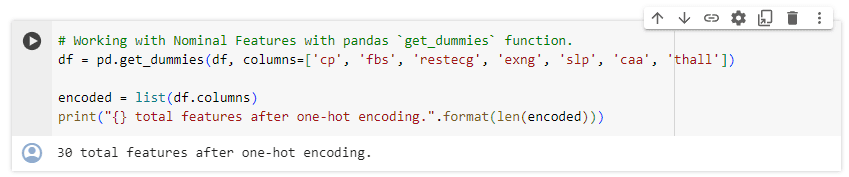
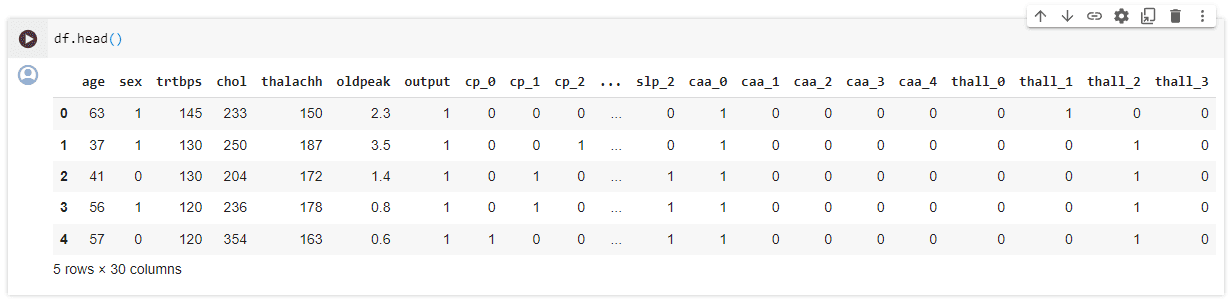
Model Building
1. นำเข้าข้อมูลที่ผ่านการ Preparation แล้ว
ข้อมูลที่ได้มีทั้งหมด 283 rows, 30 columns
2. ใช้เครื่องมือของ library PyCaret เพื่อทดลองสร้างโมเดล
2.1 ก่อนที่จะสร้างโมเดลก็ต้อง download และ import เครื่องมือที่จะใช้ก่อนแบบนี้
2.2 ใช้ setup() เพื่อตั้งค่าการทดลอง
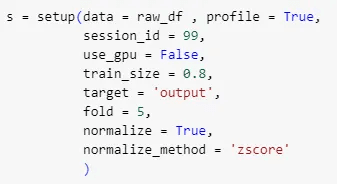
ใช้ฟังก์ชัน setup() เพื่อกำหนดตัวแปรต่าง ๆ ของการทดลอง ดังนี้
data และ profile สำหรับกำหนดข้อมูลที่จะใช้สร้างโมเดล
session_id เป็น seed สำหรับการสุ่มต่าง ๆ
use_gpu ใช้กำหนดการใช้งาน GPU ในการสร้างโมเดล (ในที่นี้ไม่ใช้ GPU)
train_size ใช้กำหนดขนาดของการแบ่งข้อมูลสำหรับ train และ test โมเดล
fold บอกจำนวน fold ที่ใช้สำหรับ cross validation
normalize เพื่อบอกให้ฟังก์ชัน normalize ข้อมูลก่อนเอาไปใช้ในโมเดล โดยที่กำหนดวิธีการที่ใช้ด้วย normalize_method = ‘zscore’ หรืออีกชื่อคือ standard normalization
เมื่อรันฟังก์ชันด้านบนก็จะได้ตารางแสดงผลลัพธ์ประมาณนี้

3. ทดลองโมเดล
เมื่อ setup เรียบร้อยแล้วก็สามารถเข้าสู่การทดลองได้เลย โดยสิ่งแรกที่จะทำคือ
3.1 เปรียบเทียบโมเดลของ algorithm ต่าง ๆ
ขั้นตอนนี้เป็นการเปรียบเทียบโมเดลของ algorithm ต่าง ๆ ที่ใช้กันทั่วไป เพื่อหาโมเดลที่เหมาะกับโจทย์ของเรามากที่สุด โดยสามารถดูได้จาก metric ต่าง ๆ ที่ใช้ในการวัดผลโมเดลแต่ละตัว สามารถทำได้ง่าย ๆ โดยใช้ฟังก์ชันตามนี้
คำสั่งนี้จะทำการทดลองสร้างโมเดลของหลาย ๆ algorithm แล้ววัดผลด้วยการทำ cross-validation ตามที่ได้ระบุไว้ในขั้น setup() แล้วเก็บโมเดลที่ดีที่สุดไว้ในตัวแปร “best” (ในค่าเริ่มต้นจะจัดอันดับโมเดลด้วยค่า Accuracy สำหรับโมเดล classification)
หลังจากนั้นจะแสดงผลของโมเดลใน metric ต่าง ๆ ในตารางแบบนี้
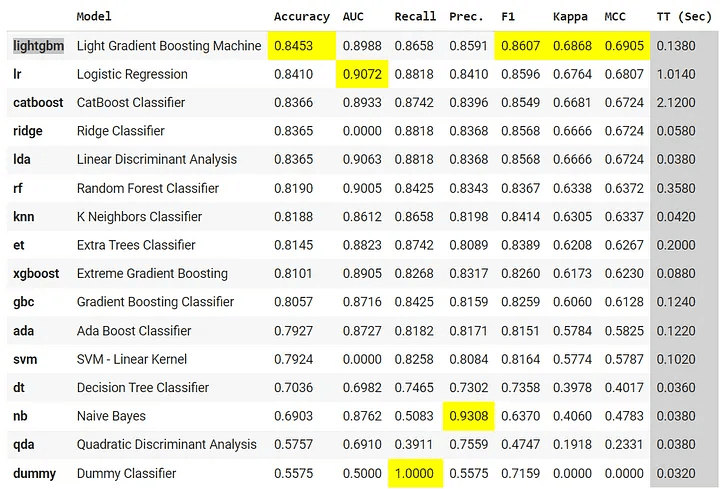
3.2 เลือกโมเดลที่ดีที่สุด
พวกเราเลือกโมเดลที่ดีที่สุดโดยดูจาก metric Accuracy และ F1-score เพราะ metric ทั้งสองเป็นค่าที่ใช้บอกความแม่นยำโดยรวมของโมเดล ไม่เหมือน Precision และ Recall ที่อาจจะเกิดจาก bias ได้ ดังนั้นโมเดลที่ดีที่สุดคือ lightgbm หรือ Light Gradient Boosting Machine
4. Model Optimization
ขั้นตอนนี้คือการปรับค่าต่าง ๆ ของโมเดล เพื่อให้ได้คามแม่นยำที่ดีขึ้น
4.1 Feature Selection
ขั้นตอนนี้คือการเลือก feature ที่มีความสำคัญกับโมเดลมากที่สุดการเลือก feature ที่ดีจะสามารถเพิ่มความแม่นยำของโมเดล และลดปัญหาการ overfitting ได้ โดยสามารถพลอตค่าความสำคัญของแต่ละ feature ได้ด้วยการใช้คำสั่ง ดังนี้
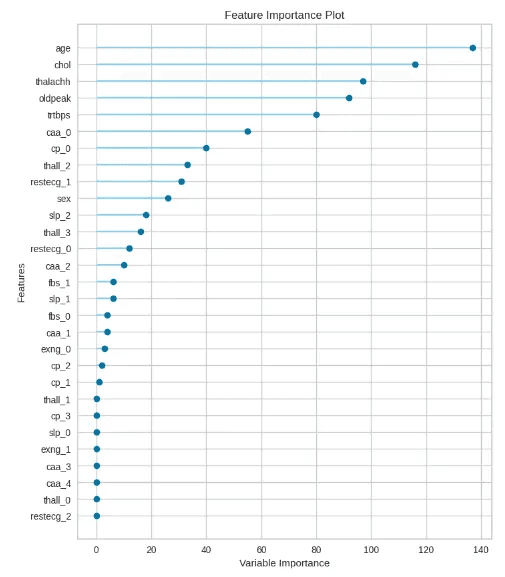
โดยวิธีการที่ใช้คือการปรับฟังก์ชัน setup() ของ PyCaret ให้ทำ Feature Selection ก่อนสร้างโมเดล ดังนี้
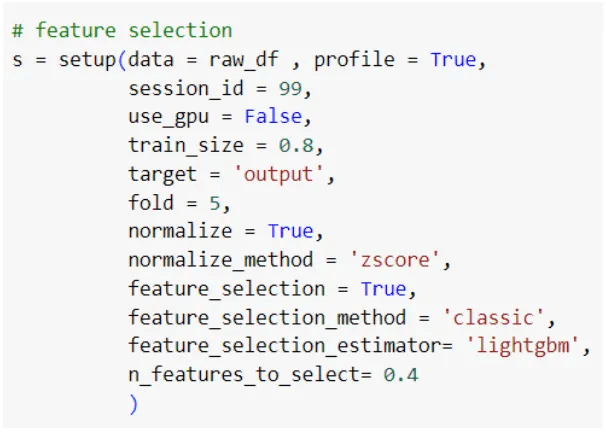
ส่วนที่เพิ่มไปเป็นส่วนที่กำหนดวิธีการทำ Feature Selection ในที่นี้กำหนดเป็น ‘classic’ หรือก็คือการ SelectKBest ของ sklearn วิธีนี้จะสร้างโมเดลพื้นฐานขึ้นมาในที่นี้คือโมเดล ‘lightgbm’ แล้วเลือก feature โดยดูจาก scoring function ที่อธิบายความสำคัญของ feature นั้น ๆ โดยสำหรับโมเดลนี้คือค่า ‘split’ แล้วก็มีการกำหนดจำนวน feature ที่ต้องการไว้ที่ 0.4 หรือ 40% ของ feature ทั้งหมด
4.2 Parameters Tuning
การทำ Parameters Tuning คือการปรับค่าต่าง ๆ ใน algorithm ของโมเดลเพื่อให้ได้ค่าความแม่นยำที่ดีขึ้น สำหรับเครื่องมือ PyCaret สิ่งที่ต้องทำมีดังนี้
4.2.1 สร้างโมเดลพื้นฐานที่ไม่มีปรับค่าอะไร โดยสามารถสร้างได้โดยใช้คำสั่งดังนี้
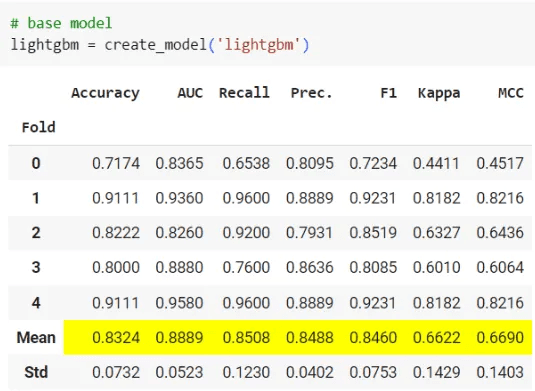
4.2.2 ใช้ฟังก์ชัน tune_model() โดยกำหนดโมเดลที่จะใช้ metric ที่ใช้เปรียบเทียบ(optimize) จำนวนครั้งที่อยากทดลอง(n_iter) วิธีการทดลอง(search_algorithm) และกำหนด choose_better = True เพื่อที่ในกรณีที่การ tune ไม่ให้ผลที่ดีขึ้น จะให้ผลลัพธ์เป็นโมเดลที่ไม่ผ่านการ tune

ผลที่ได้ก็จะเป็นโมเดลที่มีการปรับ parameter ดังนี้

5. Prediction
นำโมเดลที่ผ่านการ Optimize ไปใช้กับข้อมูล Test เพื่อวัดผลโมเดล โดยใช้คำสั่งดังนี้
ลัพธ์ที่ทำนายมีค่าความแม่นยำดังนี้

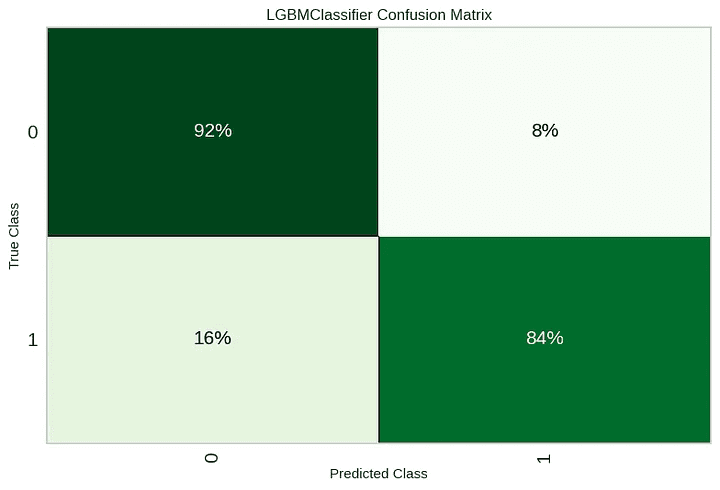
Accuracy = 0.8772
Precision = 0.9310
Recall = 0.8438
F1-score = 0.8852
plot model
Project Code:
References:
อ่านบทความ Data Science เรื่องอื่นๆ : จาก Data สู่ Insight : แนวทางขับเคลื่อนองค์กรด้วยข้อมูลลูกค้า
กลับ


